zkVM:设计ZK ASIC的新范式



原文标题:New Paradigm in Designing ZK-ASICs, the zkVM way
原文作者:Cysic 团队
感谢 Justin Drake 和 Luke Pearson 的深刻讨论。
TL;DR
实时零知识证明生成需要端到端的硬件加速。zkVM 不仅简化了 ZK ASIC 的设计,还使硬件性能更高,成本更低。
引言
零知识证明(ZKP)允许一方(证明者)向另一方(验证者)证明某个声明是真实的,且无需透露除声明本身的有效性之外的任何信息。
零知识证明的发明人之一 Silvio Micali(他与 Goldwasser 和 Rackoff 共同发明)曾表示,正如加密会混淆数据一样,零知识证明会混淆计算。更具体地说,加密算法(如 AES 或 RSA)可以将数据转换成相应的密文,这种密文隐藏了底层数据。零知识证明则将计算性声明转换为证明,这种证明不仅隐藏了计算的细节,而且验证了该声明的正确性。
ZKP 拥有两个良好的特性——零知识性和简洁性。这也让其成为了最广泛使用的高级密码学原语之一。
零知识性意味着证明本身不会泄露任何关于计算过程以及私有输入的信息。这一特性对于构建一些以隐私为导向的应用程序非常有用。例如 Aleo,它与比特币、以太坊和其他公链不同,能够隐藏交易细节。
简洁性则指的是证明的小尺寸以及短验证时间,这意味着复杂的计算过程可以转换为一小块数据(即“证明”,“proof”)。并且几乎可以在弱计算设备(比如手机、甚至树莓派)上即时验证。这一特性在扩展以太坊时极为有用,我们可以将对应 1000 笔交易的 EVM 计算转换为一个微小的证明,然后将此证明发布在以太坊上。如果这样一个小证明(可能只有 100 字节)得到以太坊的验证,那么整个 1000 笔交易便得以最终确认。私有区块链和扩展解决方案只是区块链社区中 ZKP 热潮的两个例子。利用这两个关键属性还可构建很多 ZK 项目,如 ZK 协处理器、ZK 桥、ZK 机器学习(ZKML)。
ZK 硬件加速的现状
ZKP 广泛部署的一个重大障碍是证明生成过程中对计算时间和资源的巨大需求。
通常,更复杂的计算需要更多的时间和资源。例如,在 Daniel Kang 及其团队的 ZKML 项目中,使用一台强大的 64 线程 CPU 进行 GPT-2 推理的证明生成需要超过 9000 秒。另一方面,Scroll 中的 ZK-EVM 电路的证明生成需要超过 280 GB 的 RAM。
由于这些令人望而却步的资源要求,社区正在寻求更有效的、针对 ZK 计算(指证明生成)定制的硬件。硬件选项包括CPU、GPU、FPGA和ASIC。这些选项从现已可用到不确定的等待期不尽相同。
CPU 通常被视为基线实现,用于与其他三个选项进行比较。硬件加速有两个常见的指标,下面是一些直观的解释:
性价比(Performance per dollar):这意味着用户需要支付多少钱来购买这种硬件。购买决策取决于许多因素,其中最重要的一点是同样的开销可获得的最大性能。基本而言,这一指标衡量了硬件的成本效益。通常,如果使用更先进的工艺来制造芯片,则我们可以获得更高的性能,但它往往更昂贵。
能耗比(Performance per watt):这意味着运行这种硬件需要多少能量。例如,比特大陆最新的比特币矿机 T 21 只使用 19 焦耳就能完成 1 TH 的计算,性能超过了其竞争对手的产品。
产品的优势主要取决于上述两个因素,以及部分非技术因素(如保修和残值)。通常,由于定制化的特性,基于 ASIC 的硬件在这两个指标上超过了其他三种硬件。
我们想象一下,现在已经设计出了一款专门的 ZK ASIC,其每美元和每瓦特的性能均远超现有的 GPU 和 FPGA。这款 ASIC 可以支持多种模块,如多标量乘法(MSM)、数论变换(NTT)、默克尔树等,但我们如何将这款硬件与当前的技术栈集成呢?
最常见的方法是用加速部件替换 CPU 代码中相应的计算,这种简单的替代方法通常无法实现令人满意的性能加速。我们在 ethCC’ 23 上发布了有关这种方法的发现(更多细节在这条推文中)。

CPU 和 FPGA/CPU 性能对比
与 CPU 性能相比,我们通过结合使用 CPU 和我们定制的 FPGA 机器取得了实质性进展,但性能仍远未达到最终目标——实时 ZK 证明。
这种次优的表现是由于阿姆达尔定律和不同硬件组件之间的交互成本所致。阿姆达尔定律显示,通过优化系统的单一部分获得的整体性能提升是有限的,而不同硬件模块之间的通信成本则进一步恶化了这一情况(来源于维基百科)。为了实现相对于 CPU 的显著加速,需要在单一硬件上加速每一个可能的组件。
然而,由于ZK 算法的多样性(明确地说,ZK 算法指的是 ZK 证明生成中的计算操作),这似乎是不可能的。例如,上述推特截图展示了三个 ZK 电路,即 Poseidon Hash、EVM 和 GPT-2 ,尽管使用了相同的证明后端(Halo 2-KZG),其中计算差异仍很大,尤其是在见证生成部分。截图还没有包括不同的证明后端(如 Plonky 2/3 和 Gnark)。
我们在这里想要表达的观点是,硬件需要足够通用,以适应 ZK 算法的各种片上计算操作。这种通用性可以通过 FPGA 和 ASIC 的混合结构实现,正如我们在 2022 年的这条推文中所提议的:
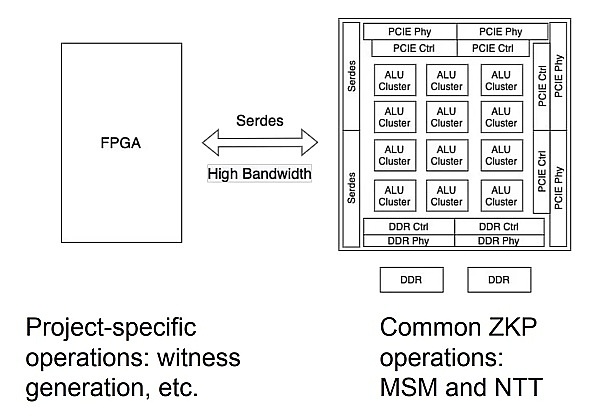
FGPA-ASIC 混合架构
在这种混合结构中,ASIC执行常见操作,而FPGA进行特定电路的计算。这两种硬件设备随后被安装在同一块PCB板上,并通过高带宽的SerDes通道连接。另外,像基于RISC-V或基于ARM的片上CPU核心,也可用于类似目的。这些混合方法通常在成本和制造质量上有极高的要求。在过去的半年里,我们一直在问自己:
“混合”是否是我们能想到的最佳结构?我们能否依靠ZK社区的技术进步来改进我们的设计?下面,我们对以上问题给出了积极的答案。
Cysic的解决之道,过去与现在
在深入技术细节之前,我们首先需要介绍一些关于零知识证明(ZKP)的基本知识。Plonkish证明系统的典型证明生成过程可以分为以下几个阶段(有关证明生成的详细解析,请阅读Scroll的这篇博客):
记录见证:见证,也被成为trace。它指的是一些数据,这些数据与其他数据共同显示了一个声明为什么是真实的。记录通过一个称为trace表的二维矩阵完成。该表中的每一个条目都是有限字段的一个元素。填充trace表的过程称为“见证生成”,这需要遍历表中的每个单元格并填入正确的值。这个过程需要在有限字段上进行算术运算,并针对特定的ZK电路进行定制。
提交见证:见证生成之后,我们获得了一个trace表,表中的每一列都通过拉格朗日插值被解释为一个多项式。然后可以使用不同的承诺机制来对这些多项式进行承诺,例如KZG和FRI。这里涉及的主要计算包括多项式乘法(MSM)、数论变换((I)NTT)、多项式拍平和默克尔树。由于在大型有限字段上进行复杂的计算,并且所需的数据量巨大,这成为了证明生成的瓶颈。
证明见证为真: 现在trace表填写完成,承诺也已经计算出来。剩下唯一要做的事情是展示trace是有效的。这意味着满足了某些特定的约束。涉及的计算包括数论变换((I)NTT)、多项式乘法(MSM)和多项式拍平。
总结来说,证明生成中的计算包括几个常见模块:如多项式乘法(MSM)、数论变换(NTT)、默克尔树和多项式拍平,以及一些额外的模块。
在我们之前的博客中,我们展示了优化这些常见模块的一些高级策略。过去几年,社区也提出了一些有望加速这些常见模块的技术(参见Ulvetanna、Ingonyama和其他团队的作品)。我们在这里不重复这些技术。
这些模块在性能方面已不再是瓶颈,但端到端的证明加速远未达到令人满意的程度。这种半成品加速器可以看作是具有一些性能提升的专用GPU版本。大致比较如下:
优势:除了传统的GPU风格的SIMD/SIMT并行计算模型,还专门支持ZK计算。这使我们能够在不依赖尖端CUDA编程技能(例如使用CUDA编写大整数操作)的情况下,全性能实施ZK操作。
缺点:编程复杂性
对于加速器来说,我们提供了类似于AI中PyTorch风格的高级编程模型,目标是提供一种“仿佛直接从论文翻译过来”的编码体验,当部分证明者被放置在加速器上时。尽管我们在硬件层面提供灵活的调度和控制能力,这仍需要理解底层的硬件设计。
对于使用CUDA的GPU用户,他们在直接使用时有相对完整的控制自由。他们可以进行任意优化。但这也意味着他们必须从零开始一切。
显然,这种半成品加速器没有实现最佳的端到端证明加速或用户友好的编程界面。我们显然需要在我们的方案中加入一些新元素。
这个新元素就是zkVM!
zkVM是什么?
虚拟机(VM)是计算机科学中的古老话题,这大体是一个可运行其他程序的程序。比如,以太坊虚拟机(EVM)就可运行以太坊智能合约,其支持的指令在这篇黄皮书中有所规定。我们知道,零知识证明系统涉及电路,因此,zkVM就是一个可以运行一系列支持指令的电路。除了执行结果,zkVM还输出一个证明,显示与指令序列相对应的VM执行轨迹是有效的。
简而言之,zkVM是一个可运行VM的ZK电路(总结自David Wong的文章)。
在zkVM设计中有两部分值得考虑:
支持的指令集:这意味着VM能执行的操作。在这个领域有几个既有的参与者,如Risc0, Succinct, Starknet, Polygon, Metis等,他们工作于不同的指令集,如RISC-V、MIPS或定制的指令集。
ZK架构:这部分涉及到与执行结果一起生成的ZK证明。ZK架构几乎与底层VM设计无关,但仍需考虑一些微妙的平衡。
zkVM设计中有一个很好的功能被称为延续(continuation)(来自RISC0)。在zkVM执行中,延续是一种机制,用于将大程序分割成几个片段,这些片段可以独立计算和证明,如下图所示:
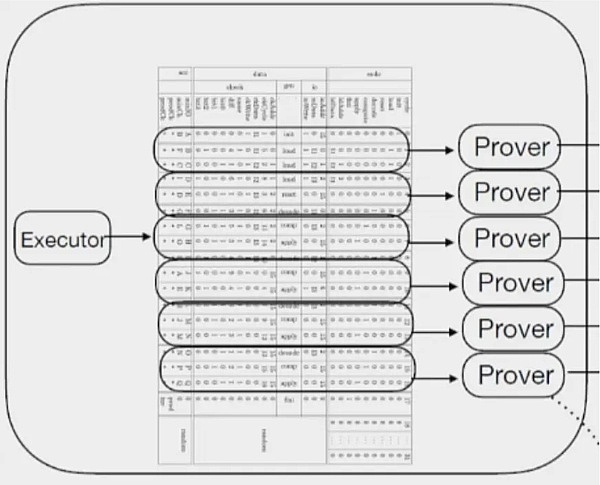
分段的过程(源:Risc 0)
这个功能之所以对硬件友好,原因如下:
并行性:由于这些切分后的片段之间互不依赖,它们可以分布到多个硬件上同时生成相应的证明。
最小化 I/O 带宽需求:zkVM 的证明生成遵循“小进小出”的模式。例如,在 Risc 0 中,证明生成的片段大小约为 50 MB,输出是一个基于 FRI 的证明,大小大约为 250 KB。这种特殊模式大大减少了 I/O 带宽的需求。
可控的内存需求:尽管每个证明生成核心的输入和输出都很小,但内存需求较大,范围在数十 GB。然而,所需内存的大小取决于片段的大小,这可以根据 zkVM 的设计进行调整。
基于这些对硬件友好的特性,我们在下文中描述了我们的硬件设计。
基于 zkVM 的硬件设计
系统的架构相对简单,由一个执行器负责执行程序,硬件负责控制并分配各个“片段(如前文所述)”,以及可配置数量的专用芯片,为每个部分的程序生成 ZK 证明。
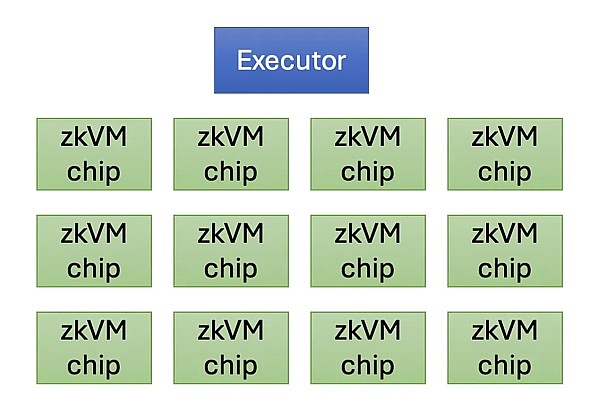
这种简单的架构使我们的硬件能够具有灵活的形式。我们可以将执行器(使用弱 CPU 或片上 CPU 核心)、一定数量的 zkVM 芯片以及其他必要的硬件组件(如内存)打包到一个机箱中。一个更简单的情况是将多个芯片打包在一个便携式机器中,就像 Macbook 充电器一样。
zkVM 硬件包括几个计算核心:
一台可编程的向量机用于向量化操作。
专用的 NTT 模块,适用于 31 位、 64 位和 256 位字段。
专用的 MSM 模块,支持 BN 254、BLS 12 – 377 和 BLS 12 – 388 曲线。
可配置的哈希函数单元,用于基于字段操作的哈希函数。
除了 zkVM 带来的优势外,这种设计 ZK-ASIC 的新范式也转化为了众多优秀的产品,可供个人或企业使用,如下所示:

ZK ASIC 产品
诚挚欢迎合作
Cysic 这一 zkVM 硬件项目旨在构建一个性能成本效益高效的硬件,适用于广泛的用例、性能和开发生产力。我们寻求多样化的视角、创新的想法以及坚定的投入,以改善和拓展我们的硬件设计。我们期待社区的参与和意见,并准备为有意参与的任何人提供指导和支持。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管93.02
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.21
- 监管中FXBTG10-15年 | 澳大利亚监管 |83.48
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47
- 监管中OneRoyal10-15年 | 澳大利亚监管 | 塞浦路斯监管 | 瓦努阿图监管85.75
- 监管中易信easyMarkets15-20年 |澳大利亚监管 | 塞浦路斯监管85.38
- 监管中FXCC10-15年 | 塞浦路斯监管 | 直通牌照(STP)85.26