Groq:最快AI推理芯片,对产业影响几何?


一、事件缘起:
近期,AI硬件初创公司Groq引发关注,其推出的基于自身LPU架构的开源大模型推理解决方案,相比现有基于GPU架构的方案,吞吐量高4倍且费用仅为现有方案的1/3。
随着AI技术的快速迭代,如何提升输出端的响应速度愈发重要,而近期Sora Demo的惊艳效果,让业内看到了应用场景爆发的可能性,但如果延迟过高,会显著影响使用体验,因此Groq官网所展示的运行速度引起业内广泛讨论。在前段时间的基准测试中,Groq LPU 推理引擎上运行的Llama2 70B直接刷榜。
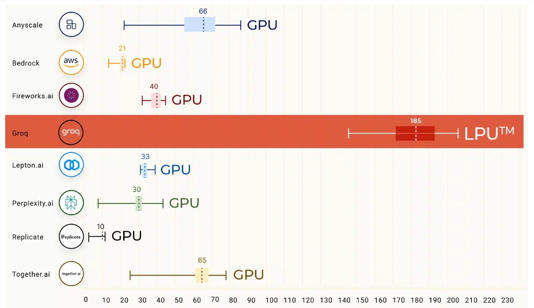
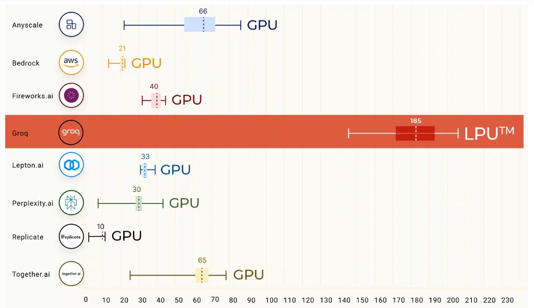
数据来源:Groq公司官网
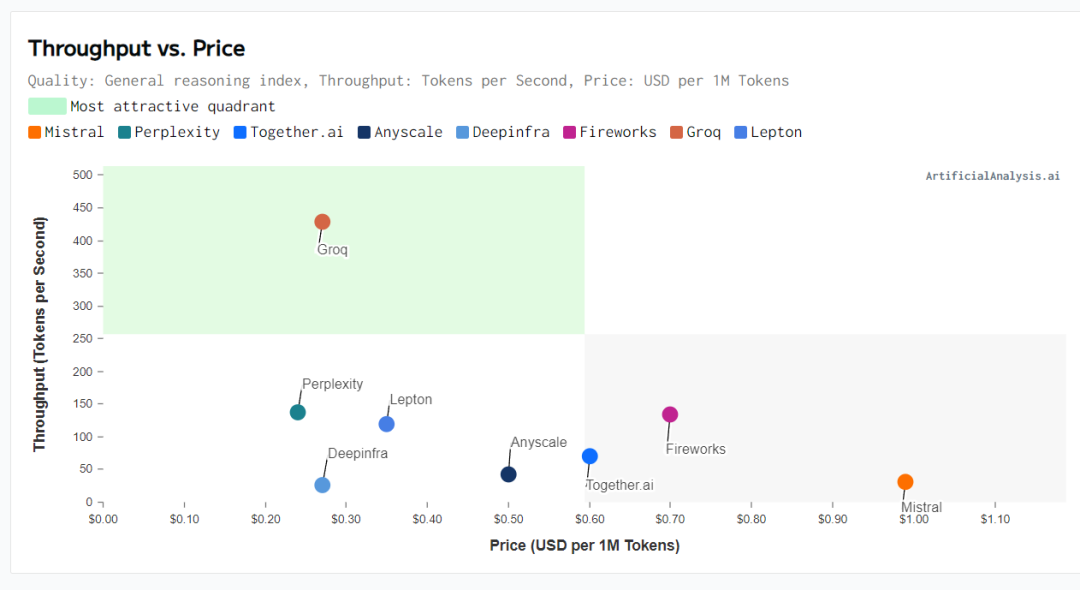
参考 Artificial Analysis.ai 数据,Groq 推出的 Mixtral 8x7B Instruct API,以430token/s的速度,刷新业界历史记录。而且其每百万个token的价格仅为0.27美元,击败了Mistral、Lepton等。
数据来源:Groq公司官网
二、Groq发展历程
Groq成立于2016年,总部位于美国加州,创始人Jonathan Ross是前谷歌高级工程师,也是谷歌自研AI芯片TPU团队的核心成员,产品主管John Barrus曾在谷歌及亚马逊团队担任产品高管。公司产品LPU(Language Processing Units)是一款新型的AI芯片,虽然公司团队脱胎于谷歌TPU,但在技术路线的选择上选择了LPU这个全新的系统路线。目前公司芯片采用格罗方德的14nm工艺,而在23年8月,Groq宣布,三星的Taylor工厂将生产其4纳米AI加速器芯片。
融资方面,2017年,公司获得了风险投资家Chamath Palihapitiya投资1030万美金;2021年4月,又从D1 Capital 、Tiger Global Fund等金融机构获得了3亿美金的融资,估值超过10亿美元。23年还进行了一轮5000万美元的安全可转换债务融资,目前团队正在进行新一轮的筹资活动。
三、Groq技术原理
Groq芯片采用的是14nm工艺,搭载了230MB的SRAM来保证内存带宽,片上内存带宽可达80TB/s,不同于GPU和CPU通用芯片架构,Groq开发的是针对大语言模型的定制化芯片,其LPU技术核心解决的是计算密度和内存带宽两大瓶颈。如下图所示,LPU将更多的空间留给了计算单元,从而展现了更高的计算能力,这使得单个数据处理时间显著减少,从而可以快速地输出文本序列。它使用时序指令集计算机架构(Temporal Instruction Set Computer),因此不必频繁地在HBM(高带宽内存模组)加载数据,而是直接利用SRAM来进行数据的处理,其速度比GPU中用的存储模组快20倍。

数据来源:Groq公司官网
四、前景判断
综上所述,Groq芯片的特点是大算力小内存,速度快但单卡吞吐能力有限,需要更多的卡来保证同等级别的吞吐能力,这就意味着更高的成本,目前Groq想要在低延迟领域建立竞争优势,就需要拓宽应用场景并进一步降低总成本。原阿里技术副总裁贾扬清做过估算:
由于Groq芯片单卡内存仅为230MB,在运行LLaMa2 70B大模型时,假设使用int8量化技术,需要使用572张卡,每张卡的价格为20000美元,因此购卡成本约为1144万美元;同时每张卡的功耗平均为185W,则总功耗为105.8Kw,目前数据中心电费为200美元/月,则运用过程中产生的年度电费为25.4万美元,因此假设运行三年,Groq的总成本约为1220万美元。
而运行同样参数体量的模型,英伟达H100卡仅需8张,购置成本约为30万美元,一个8卡的H100服务器的功耗约为10kw,则运营过程中的年度电费为2.4万美元,因此假设运营三年,总成本为37.2万美元。
从结果上看,LPU展现出来的推理能力,虽然在成本上仍不满足实际应用的需求,但仍对AI行业带来了冲击和新的思路,未来随着硬件技术和生产层面的逐步成熟,成本端有望得到改善,届时LPU或将提供新的发展路线。
AI行业日新月异,不存在规律的产品更新规划,这一点从Sora的突然问世、Deepmind Genie模型的发布等事件皆可得到验证。站在投资者角度,AI产业投资技术门槛高、技术发展快、产品迭代频率高,且价格上呈现较大波动,更适宜用AI相关指数指数进行低位定投,降低选股风险和择时难度。同时,考虑到AI主权的影响,尽管人工智能海内外发展存在差异,国内人工智能产业仍存在较大的软硬件市场,相关的投资机会包括人工智能ETF(159819),场外联接(A类:012733;C类:012734)、半导体芯片ETF(516350),场外联接(A类:018411;C类:018412)等。
以上内容与数据,与界面有连云频道立场无关,不构成投资建议。据此操作,风险自担。
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管93.02
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.21
- 监管中FXBTG10-15年 | 澳大利亚监管 |83.48
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47
- 监管中OneRoyal10-15年 | 澳大利亚监管 | 塞浦路斯监管 | 瓦努阿图监管85.75
- 监管中易信easyMarkets15-20年 |澳大利亚监管 | 塞浦路斯监管85.38
- 监管中FXCC10-15年 | 塞浦路斯监管 | 直通牌照(STP)85.26