一文了解FPGA和GPU加速零知识证明计算的优缺点



零知识证明技术应用越来越广,隐私证明,计算证明,共识证明等等。在寻找更多更好的应用场景的同时,很多人逐步发现零知识证明证明性能是个瓶颈。Trapdoor Tech 团队从 2019 年开始深入研究零知识证明技术,并一直探索高效的零知识证明加速方案。GPU 或者 FPGA 是目前市面上比较常见的加速平台。本文从 MSM 的计算入手,分析 FPGA 和 GPU 加速零知识证明计算的优缺点。
摘要
ZKP 是拥有未来广泛前景的技术。越来越多的应用开始采用零知识证明技术。但 ZKP 算法比较多,各种项目使用不同的 ZKP 算法。同时,ZKP 证明的计算性能比较差。本文详细分析了 MSM 算法,椭圆曲线点加算法,蒙哥马利乘法算法等等,并对比了 GPU 和 FPGA 在 BLS 12 _ 381 曲线点加的性能差别。总的来说,在 ZKP 证明计算方面,短期 GPU 优势比较明显,Throughput 高,性价比高,具有可编程性等等。FPGA 相对来说,功耗有一定的优势。长期看,有可能出现适合 ZKP 计算的 FPGA 芯片,也可能为 ZKP 定制的 ASIC 芯片。
ZKP 算法复杂
ZKP 是个零知识证明技术的统称(Zero Knowledge Proof)。主要由两种分类:zk-SNARK 以及 zk-STARK。zk-SNARK 目前常见的算法是 Groth 16 ,PLONK,PLOOKUP,Marlin 和 Halo/Halo 2 。zk-SNARK 算法的迭代主要是沿着两条方向: 1/ 是否需要 trusted setup 2/ 电路结构的性能。zk-STARK 算法的优势是毋需 trusted setup,但是验证计算量是对数线性的。
就 zk-SNARK/zk-STARK 算法的应用来看,不同项目使用的零知识证明算法相对分散。zk-SNARK 算法应用中,因为 PLONK/Halo 2 算法是 universal(无需 trusted setup),应用可能越来越多。
PLONK 证明计算量
以 PLONK 算法为例,剖析一下 PLONK 证明的计算量。
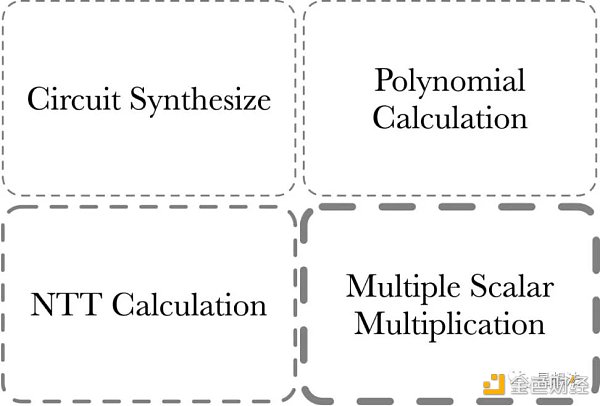
PLONK 证明部分的计算量由四部分组成:
1/ MSM - Multiple Scalar Multiplication。MSM 经常用来计算多项式承诺。
2/ NTT 计算 - 多项式在点值和系数表示之间变换。
3/ Polynomial 计算 - 多项式加减乘除。多项式求值(Evaluation)等等。
4/ Circuit Synthesize - 电路综合。这部分的计算和电路的规模 / 复杂度有关。
Circuit Synthesize 部分的计算量一般来说判断和循环逻辑比较多,并行度比较低,更适合 CPU 计算。通常来讲,零知识证明加速一般指的是前三部分的计算加速。其中,MSM 的计算量相对来说最大,NTT 次之。
What's MSM
MSM(Multiple Scalar Multiplication)指的是给定一系列的椭圆曲线上的点和标量,计算出这些点加的结果对应的点。
比如说,给定一个椭圆曲线上的一系列的点:
Given a fixed set of Elliptic curve points from one specified curve:
[G_ 1, G_ 2, G_ 3, ..., G_n]
以及随机的系数:
and a randomly sampled finite field elements from specified scalar field:
[s_ 1, s_ 2, s_ 3, ..., s_n]
MSM is the calculation to get the Elliptic curve point Q:
Q = \sum_{i= 1 }^{n}s_i*G_i
行业普遍采用 Pippenger 算法对 MSM 计算进行优化。深入看看 Pippenger 算法的过程的示意图:
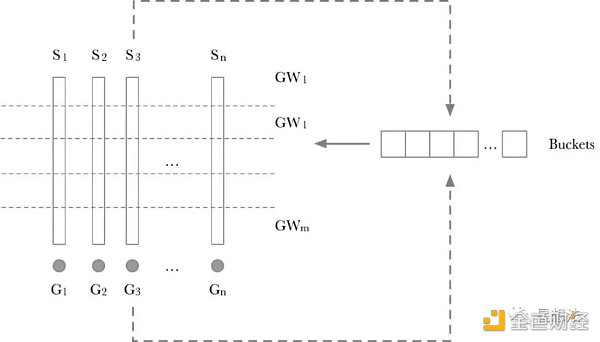
Pippenger 算法的计算过程分成两步:
1/ Scalar 切分为 Windows。如果 Scalar 是 256 bits,并且一个 Window 是 8 bits,则所有的 Scalar 切分为 256/8 = 32 个 Window。每一层的 Window,采用一个「Buckets」临时存放中间结果。GW_x 就是一层上的累加结果的点。计算 GW_x 也比较简单,依次遍历一层中的每个 Scalar,根据 Scalar 这层的值作为 Index,将对应的 G_x 加到相应的 Buckets 的位上。其实原理也比较简单,如果两个点加的系数相同,则先将两个点相加后再做一次 Scalar 加,而不需要两个点做两次 Scalar 加后再累加。
2/ 每个 Window 计算出来的点,再通过 double-add 的方式进行累加,从而得到最后的结果。
Pippenger 算法也有很多变形优化算法。不管怎么说,MSM 算法的底层计算就是椭圆曲线上的点加。不同的优化算法,对应不同的点加个数。
椭圆曲线点加(Point Add)
你可以从这个网站看看具有「short Weierstrass」形式的椭圆曲线上点加的各种算法。
http://www.hyperelliptic.org/EFD/g 1 p/auto-shortw-jacobian-0.html#addition-madd-2007-bl
假设两个点的 Projective 坐标分别为(x 1, y 1, z 1) 和 (x 2, y 2, z 2) ,则通过如下的计算公式可以计算出点加的结果 (x 3, y 3, z 3)。

详细给出计算过程的原因是想表明整个计算过程绝大部分是整数运算。整数的位宽取决于椭圆曲线的参数。给出一些常见的椭圆曲线的位宽:
BN 256 - 256 bits
BLS 12 _ 381 - 381 bits
BLS 12 _ 377 - 377 bits
特别注意的是,这些整数运算是在模域上的运算。模加 / 模减相对来说简单,重点看看模乘的原理和实现。
模乘(Modular Muliplication)
给定模域上的两个值:x 和 y。模乘计算指的是 x*y mod p。注意这些整数的位宽是椭圆曲线的位宽。模乘的经典算法是蒙哥马利乘法(Montgomery Muliplication)。在进行蒙哥马利乘法之前,被乘数需要转化为蒙哥马利表示:
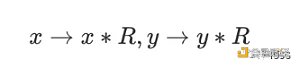
蒙哥马利乘法计算公式如下:
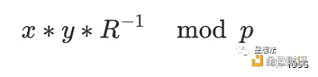
蒙哥马利乘法实现算法又有很多:CIOS (Coarsely Integrated Operand Scanning),FIOS(Finely Integrated Operand Scanning),以及 FIPS(Finely Integrated Product Scanning)等等。本文不深入介绍各种算法实现的细节,感兴趣的读者可以自行研究。
为了对比 FPGA 以及 GPU 的本身的性能差别,选择最基本的算法实现方法:
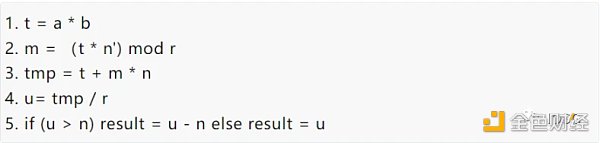
简单的说,模乘算法可以进一步分成两种计算:大数乘法和大数加法。理解了 MSM 的计算逻辑的基础上,可以选择模乘的性能(Throughput)来对比 FPGA 和 GPU 的性能。
观察和思考
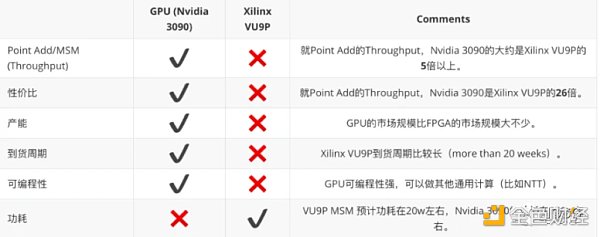
在这样的 FPGA 设计下,可以估算出整个 VU 9 P 能提供的在 BLS 12 _ 381 椭圆曲线点加 Throughput。一个点加(add_mix 方式)大约需要 12 个模乘。FPGA 的系统时钟为 450 M。

在同样的模乘 / 模加算法下,采用同样的点加算法,Nvidia 3090 的点加 Troughput(考虑到数据传输因素)超过 500 M/s。当然,整个计算涉及到多种算法,可能存在某些算法适合 FPGA,有些算法适合 GPU。采用一样的算法对比的原因,想对比 FPGA 和 GPU 的核心计算能力。
基于上述的结果,总结一下 GPU 和 FPGA 在 ZKP 证明性能方面的比较:
总结
越来越多的应用开始采用零知识证明技术。但 ZKP 算法比较多,各种项目使用不同的 ZKP 算法。从我们的实践工程经验来看,FPGA 是个选项,但是目前 GPU 是个性价比高选项。FPGA 偏好确定性计算,有 latency 以及功耗的优势。GPU 可编程性高,有相对成熟的高性能计算的框架,开发迭代周期短,偏好需要 throughput 场景。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管93.02
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.21
- 监管中FXBTG10-15年 | 澳大利亚监管 |83.48
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47
- 监管中OneRoyal10-15年 | 澳大利亚监管 | 塞浦路斯监管 | 瓦努阿图监管85.75
- 监管中易信easyMarkets15-20年 |澳大利亚监管 | 塞浦路斯监管85.38
- 监管中FXCC10-15年 | 塞浦路斯监管 | 直通牌照(STP)85.26