行业数据+场景:AI风口下,率先利好的是这样的公司


01 引言
2023创投圈热度最高的话题非AI赛道莫属。从国外OpenAI、Google等推出AI杀手级应用,到百度等大厂追赶ChatGPT,推出属于中国的通用大模型,就连美团联合创始人王慧文、搜狗公司前CEO王小川等行业大咖也躬身入局,资深NLP专家也纷纷下场。截至5月16日,已有255家AI企业/产品被收录在“生成式AI圈子”小程序,还有更多基于大语言模型(LLM)为创业起点的企业正在涌入市场。热闹之下,新一代AI行业的机会究竟在何处?
非凡产研经过数月以来不断跟行业内创业者、专家以及AI方向投资人进行深入交流,观察到中国当前AI竞争中首先获得参赛资格的是具有前瞻性视野、拥有模型自训练技术和工程能力,深入运用模型应用到垂直场景,形成商业解决方案的企业。
我们还深度采访了四家自训练模型并且应用到垂直场景,快速实现商业化的企业。分别是必优科技的创始人周泽安、澜舟科技创始人周明、秘塔科技COO王益为和睿企科技董事长于伟,深度剖析为什么这类企业能够在AI创业浪潮中率先把握机会以及为什么行业模型是中国产业数智化的关键。
必优科技
必优科技是一家专注于人工智能领域的智能可控内容生成技术(AICGC,AI-Control Generate Content)的科技型公司,致力于向企业提供30+垂直行业内容的智能创作SaaS服务,驱动内容创作效率革新,同时为企业提供一站式垂类行业模型应用构建(AIGC模型训练,API接口与低代码web应用)的SaaS平台解决方案。
澜舟科技
澜舟科技是一家业界领先的认知智能公司,致力于以自然语言处理(NLP)技术为基础,为全球企业提供新一代认知智能平台,助力企业数字化转型升级。其主要产品是基于“孟子预训练模型”打造的一系列功能引擎(包括搜索、生成、翻译、对话等)和垂直场景应用。
秘塔科技
秘塔科技是是人工智能领域的一家新锐科技公司,致力于将重复脑力劳动AI化,以AI为杠杆撬动专业场景的百倍生产力提升。目前,秘塔科技已经拥有近千万用户,成立北京和成都两大研发中心,在文本AIGC、文档辅助创作、法律专业场景等方向上开展研发与产品落地。
睿企科技
睿企科技是一家深耕垂直领域大模型的人工智能公司,致力于通过领先的多模态大模型和认知决策大脑让每一个组织和个人都能拥有专属自己的个性化AI大脑。公司已经在政务、法务、金融、教育、营销等多个行业落地,产品包括法务合规审核机器人、案件研判机器人、个性化助理机器人等一系列AI产品。
02 为什么要做自训练模型?
•如何定义自训练模型?•
自训练模型是指基于Transformer架构*,使用了大量的预训练数据和自监督学习方法,可以完成各种自然语言处理任务。
Transformer架构*:最早是由Google于2017年在「Attention is all you need」一文中提出,在论文中该模型主要是被用于克服机器翻译任务中传统网络训练时间过长,难以较好实现并行计算的问题。
相当于从零搭建、训练语言模型,如BERT、GPT、T5等模型都是基于类似的架构训练。基于行业数据所搭建的自训练模型,往往具备可私有化,开源的特点。
本文受访的必优科技、澜舟科技、秘塔科技和睿企科技,均为具有自训练模型并且已率先应用到行业场景,快速实现商业化的企业。
• 自训练与利用API应用开发有什么不同?•
如果从构建商业模式壁垒来说,随着通用模型以超乎人类想象的速度优化延伸其基础能力,越是靠近基础功能的应用越危险。
Jasper AI近期的局面就说明了该问题。
Jasper AI是美国一家2021年成立的专注营销领域内容创作的公司,Jasper AI是GPT生态早期的最大赢家之一。在ChatGPT发布前,用户难以直接使用LLM的语言理解与生成能力,由此Jasper基于GPT-3模型的API,通过模型的微调(fine-tune)*打造了营销内容生成平台,用户量超过10万,成立短短18个月的时间估值快速增长到15亿美元。然而ChatGPT的问世,取代了Jasper提供的部分基础功能,免费的同时兼具极佳的易用性,大部分中小客户的需求可以直接通过ChatGPT满足。这给Jasper的定价带来极大压力,Jasper的优势大大减弱。有消息称,其上轮投资方在ChatGPT成为C端现象级应用时就已经考虑出售其股份了。
模型的微调(fine-tune)*指在一个已经训练好的模型的基础上,使用新的数据集或者任务对模型进行进一步的训练,以适应特定的任务或者数据。通常情况下,fine-tune会调整模型的参数,使得模型可以更好地拟合新的数据集或者完成新的任务。
如果从开发到商用的难度及成本的角度来说,无疑API应用开发是最快最便捷的,自训练模型的搭建包括了多个复杂环节,包括模型的复杂度、数据的质量和数量、算法的选择和实现、计算资源的可用性、团队的经验和技能等等。在一般情况下,自训练模型从开发到商用的时间可能需要数月或数年的时间不等。
例如必优科技所训练的垂直行业语言模型(SLLM)模型耗时14个月,该模型为专注于NLP下的细分CTG(Control Text Generate)方向的行业模型。
在创业公司的生存压力下,形成商业解决方案并成功服务客户才是最重要的事情,在此情形下,炼丹和投喂都变得十分讲究性价比。
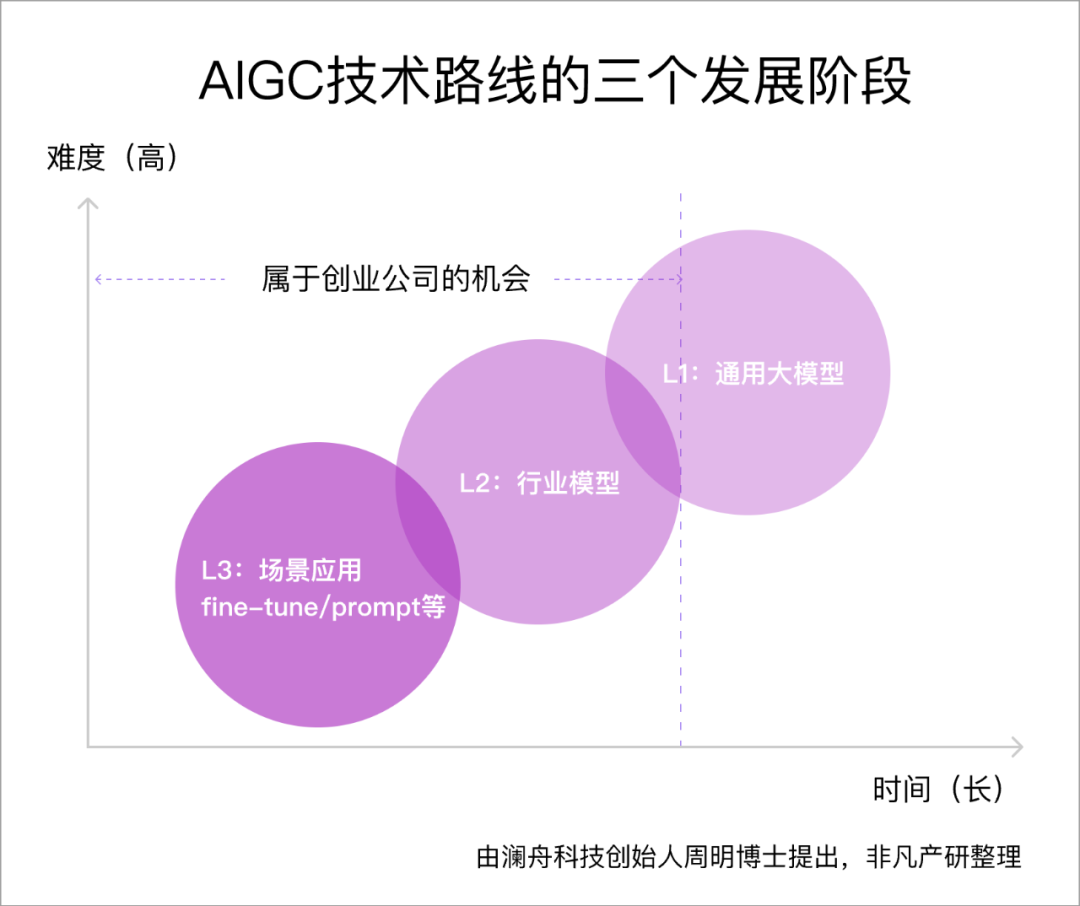
澜舟科技创始人周明博士把当前不同的AI商业解决方案技术路线类比自动驾驶发展阶段,也将AI技术路线的演进比喻成三个发展阶段。
L1(Level 1)是自研/自训练通用大模型,例如ChatGPT所使用的GPT-4模型;L2是在LLM基础上利用行业大数据,建立行业大模型,深度参与到行业使用场景当中;L3是基于各个场景需求,在行业模型/LLM的基础上,根据具体任务,要么做fine-tune,要么做prompt工程等,来满足场景的需要。
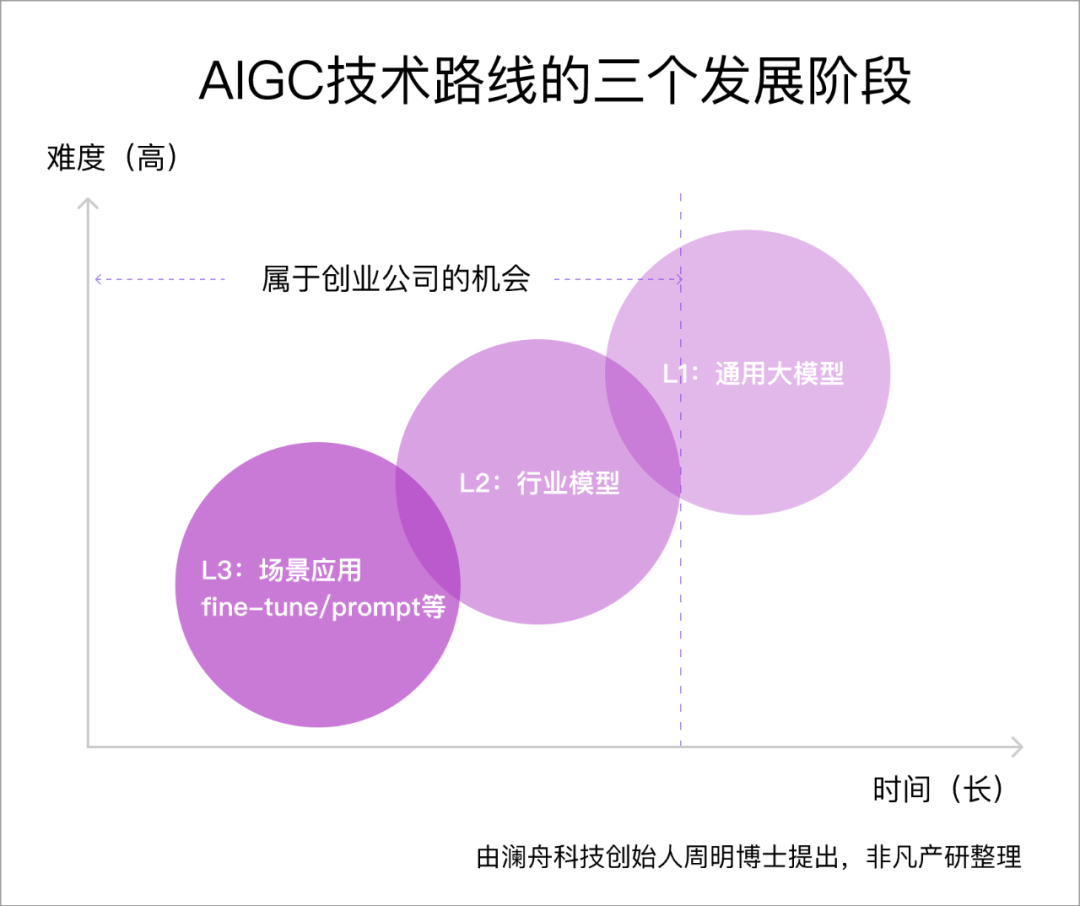
很多大模型的创业团队刚起步,大多数处在L1阶段,少数团队选择L2阶段创业。
澜舟科技从2021年就开始了自研大模型之路,并获得了创新工场、斯道资本等机构的多轮融资支持。据周明博士介绍,澜舟科技推出的“孟子”模型,其技术底座均为澜舟自训练,已经率先形成了商业闭环。而澜舟科技刚成立时就坚持选择自训练模型路径,贯穿L1到L3,并率先形成商业化解决方案。此举从今天看来颇具先见之明。
以金融行业为例,现有的LLM无法深入到金融行业的业务场景之中,即使使用大厂的LLM模型,也不会给客户做定制化的fine-tune。所以澜舟科技选择了在自研LLM的基础上,自训练行业模型,服务于金融行业的客户,可私有化部署,可基于客户数据训练,深度参与到行业业务场景之中。
必优科技的创始人周泽安认为,模型的生成可控性非常重要,自训练可以完全掌控生成的质量。
“通用大模型可以迅速达到60分,而必优科技的自训练模型能够做到在核心场景里面从60分到90分。”
模型的可控生成可以满足可信、可控的要求。而如果仅使用通用模型的基础微调,其提供给下游场景模型的可控fine-tune优化空间有限。
睿企科技董事长于伟博士提出,尽管基础通用大模型已经达到优秀高中毕业生甚至未来达到优秀本科毕业生的水平,但是在实际落地应用中所需要的模型能力更多是专业的能力,需要专业的知识和数据进行训练,而这类知识和数据大多是私有数据,不能对外开放。因此,睿企科技自2018年成立之初就致力于基于Transformer的行业垂直大模型的训练,为行业提供具备专业能力的NLU(自然语言处理解)和NLG(自然语言生成)大模型。
03 行业大模型,是中国当前最容易看清楚的属于创业公司的好机会
行业模型是指,依托特定行业自有数据,结合行业场景,通过自训练或基于开源通用模型的API做应用开发的模型。
• 通用大模型入局成本过高,行业模型有更多创业机会 •
通用大模型的创业成本极其高昂,例如在算力成本方面,1750亿参数的GPT-3用到了上万块A100芯片,机时费用是460万美元,资金花费就高达1200万美元。
澜舟科技创始人周明博士指出,假设组建10到20人的团队,购买500块到1000块GPU,每年最便宜大概也要投入5000万人民币作为研发费用,能够训练出一个百亿数据级别的模型,如果训练千亿级模型就在需要大概再投入7-10倍的资金,相当于两亿到三亿人民币左右。
睿企科技董事长于伟博士指出,随着用户对模型能力的期望和要求不断变高,模型参数和训练数据也需要不断增加,受限于训练成本,未来只有像微软和谷歌这类既有技术又有应用场景、还具备超级财力的互联网高科技公司才有可能在通用大模型训练进行持续的投入。
当前国内研发LLM的团队至少30家,如百度、MiniMax和智谱AI等,均为资金,人才,资源、经验密集的大公司及知名创业者领衔。属于大多数创业者的机会并不在通用大模型领域。
相比LLM,行业模型的创业并不需要自己训练通用大模型,可以直接基于最先进的开源模型或API进行二次训练,模型训练成本大幅降低。
不需要一开始就对标GPT3.5做千亿级参数的大模型,减少模型参数量反而使得训练的算力成本下降、复杂度降低,在小样本学习下进行多次有效的训练,从而迅速获得know-how和产品反馈。
减少模型参数之后,训练一次的成本甚至能够从几百万美元减小到几十万美元。那么就得以在特定领域对模型进行多次训练,此时与通用大模型就形成了差异化优势。并且相对低的成本会带来客户可承受的定价,尤其是在结合客户数据的二次训练阶段和使用阶段的成本要低很多。
秘塔科技COO王益为提出创业公司难以兼顾的三个难点,即“不可能三角”:投入的成本、模型的多样性和模型的可信度。除非有无穷无尽的资金、资源可以投入,大多数模型只能做到其中一点或者兼顾两点,即使 OpenAI 也达不到三者兼顾的程度。
周明博士提出,澜舟科技目前并没有做千亿级的大模型,除了成本考量,一个重要原因就是客户目前没有那么强的需求,必须做一个千亿级大模型。在很多场景,客户需要低成本且适用的模型。
必优科技周泽安认为,通用大模型的基础底座很重要,给各行各业整体带来了在泛化生成能力上的提升,但在如何利用通用模型打造出满足业务场景的下游模型更为关键,虽然大模型目前已经显现出在特定场景的具象处理能力,但其在实际应用的可控生成能力(可控输入/输出、可信可塑内容)却要弱于场景模型。针对在特定场景和特定用途的数据集上训练更精细的模型,所以必优科技依托于自研 RFKL智能算法范式迅速尝试了90多个场景模型(伯乐、商贾、图芴三大系列),并基于精准的高价值用户反馈数据,可实现模型自我优化。
睿企科技于伟博士提出,睿企科技的产品即是从模型的专业性和实战价值出发,不盲目追求模型参数规模,而是专注与针对行业中需要的专业能力,训练能满足要求的性价比最高的模型,解决逻辑应用过程中遇到的算力不足的问题。
• 行业模型的壁垒在于场景和数据 •
GPT为代表的通用大模型涌现出惊人的理解和生成能力以及强大的知识储备。但是通用大模型可以全方位碾压行业模型吗?周明博士指出,“通用大模型是万能的,这只是一个幻觉。”
在处理海量数据、重复性流程和追求个性化的C端场景,通用大模型会更有优势;而在非常专业的To B场景,例如金融、法律和医疗等一些对输出内容的精准度以及质量要求比较高的行业,需要在通用模型的基础上加入私密且专业的高价值数据集进行模型训练和工作流程优化,才能满足专业场景的需求。
如果能够掌握充足且独特的数据量,不单纯依赖第三方API,选择垂直化方式(自训练模型应用于面向用户的应用),垂直整合场景中复杂度足够深的任务,快速迭代,寻找真实的闭环场景和用户反馈,从而建立竞争壁垒。
此外,由于通用模型和行业模型的用户群体差异较大,因此反馈数据有较大差异,使得由垂直行业模型生成的内容更能符合特定垂直场景的需求,生成质量和深度也会更高。用于RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)的高质量用户反馈也起到非常关键的作用,有助于不断推动模型产出的内容质量进一步提升。
这也说明了行业模型,数据为先,场景为王。
睿企科技于伟博士以公检法行业为例,提到执法办案工作人员的工作量大、涉及的各种文书种类很多、流程繁琐、对合规要求相当高,而文书材料也是执法办案过程中的关键部分,不能有一点瑕疵。公检法行业有极大的刚性需求、每年也有大量的预算投入,并且拥有很多高质量数据。睿企科技结合公检法部门的业务需求,基于通用大模型,把专属数据和业务知识放在定制化的多模态垂直大模型里面,帮助公检法部门训练专属AI大脑,推出一系列基于大模型的简单易用的AI产品,包括执法办案智能合规审核机器人、智能接处警机器人等,解决工作痛点提升效率。
秘塔科技COO王益为表示,法律咨询场景的核心问题在于不能直接使用通用模型,因为LLM的目前存在Hallucination(机器幻觉,指事实性错误),阻碍了B端的法律场景深度应用。通过一个字去预测下一句,这种技术方式在法律咨询的领域里行不通。所以对于创业公司来说,首先资源是非常有限的,那么一定要选择具有特色的一些场景,比如行业付费意愿强,并且对于可信度要求极高的领域。
必优科技基于Transformer架构,引入了自研WCCG(Wernicke Control Content Generate)模型,并在中间加了一层融合,通过可控的方式去生成模型,并且拥有独创的 RFKL 智能算法范式。通用模型本身有很强的知识性,但是精确度方面,通用模型只能解决的是 6 、7成的问题。必优科技则通过场景倒推模型的机制,基于精准的高价值用户反馈数据,通过数据飞轮强化对场景模型的内容生成方向进行引导,实现模型自我优化,在特定场景中需要专门优化模型来提升生成质量,重塑以数据为驱动的内容创作新模式。必优科技在用模型尝试了近百种行业场景后,依据反馈聚焦在了人力招聘、办公office场景。
“自训练特定的场景模型不仅是单纯的在技术层面实现,还要配合对数据的理解,实打实的去扎根到了解这个行业的本质,或者内容到底输出是给谁用?这样才能反向定义数据去训练。”
澜舟科技创始人周明博士认为两年后没有人再会谈论大模型,因为它已经成为基础设施了,行业竞争格局将会稳定,通用大模型领域不再会出现新的创业机会。那就意味着将会就有很多公司倒闭或者转型,这些团队的从业人员在市场上面将会形成很强的技术外溢效应,或者将在非大模型行业内渗透。同时意味着即使是通用大模型做的很好的企业也不能仅仅依赖模型业务,也应该更多去发展各自的生态或者在这基础上做一些新的运营。
• 行业模型可以与通用模型LLM并存 •
目前行业内共识是中国一定要有自己的大模型,大厂一定会专注在全力迅速地建立通用大模型能力。这给创业公司留出了生存空间。
在C端,由于大厂的流量、规模效应和千亿大模型的通用性,创业公司的机会将被大量挤兑,需要在夹缝中寻找机会,做大厂没有形成共识的方向;在B端,大型客户大概率不会使用大厂的产品,而倾向于选择可定制的私有化部署解决方案。
行业模型创业公司需要具备特定领域的独有关键数据,在具体场景上又快又好的解决问题,兼具私有化部署能力,就可以与通用模型LLM并存,在行业中找到生态位。
秘塔科技COO王益为提出只要选取自己真正懂的场景,即使巨头都已经布局,秘塔科技仍然在细分领域里面有机会和提升的空间。而在法律行业,对于生成文本的多样性要求并不是特别高,但是对于法律服务的严谨度和可信度要求特别高。秘塔科技在选择技术路线和产品路线上有一些思考,秘塔科技的模型本身就是为了文生文的任务去做的单一任务训练,相应去精心准备数据库,在专项文本上进行强化和训练,形成正式文件的文风,这就是秘塔科技竞争的优势。
在直接向C端提供文本AIGC服务的产品中,秘塔科技拥有最多的用户(近千万);在法律行业中,秘塔科技的现有用户覆盖数千家律师事务所和公司法务部。
睿企科技于伟博士指出,尽管行业模型创业不需要从头训练通用大模型,但是挑战同样存在。行业模型创业需要业务、数据、模型的有机融合,因为用户只会采购能满足他们需求的性价比最高的服务和产品。如何找到一个巨大的市场并把产品和服务做到极致,成为行业头羊,是每个垂直行业模型创业公司必须面对的挑战。
• 行业模型很有可能是中国产业数智化的最后一公里 •
这一波AI被称为第四次工业革命,将彻底改变每一个行业。阿里董事会主席张勇提出“所有行业都值得用大模型重做一遍”。
即便中国在通用模型技术上是跟随者,但并不代表着中国市场会参照美国市场而发展。
美国的AI赛道创业环境,以OpenAI为例,活跃开放的资本市场、充足的算力资源和人才更适合“大力出奇迹”路线;中国的创业环境更加看重技术应用的深度,中国创业者擅长在产业应用里创新。陆奇博士在奇绩创坛的演讲中表示,中国的重要优势在于政府在AI领域的投入、支持和重视程度高于其他国家。
睿企科技于伟博士提到,十三五期间中国政府在公检法领域投入数万亿,催生了一大批人工智能企业的高速发展和上市,加速了人工智能技术的发展。十四五期间,中国政府在大模型上的持续投入也会缩小和美国的差距,并在很多领域超过美国。
美国从上世纪90年代就开始了数字化浪潮,相比于美国而言,中国企业尚处于数字化转型初期,中国有大量亟待数字化转型升级的传统产业,有太多需要依赖人工智能实现效率提高的业务场景。
在中国30年的产业数智化浪潮之中,一直延续着的信息化-数字化-智能化的演进路线,随着通用模型及行业模型加入到产业数智化浪潮之中,很有可能在部分关键场景率先利用AI模型达到智能化,从而倒逼产业其他工作流及场景快速形成数据沉淀,这将大大加快中国整个产业数智化的进程。
本条资讯来源界面有连云,内容与数据仅供参考,不构成投资建议。AI技术战略提供为有连云。
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管88.77
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47