金融圈重磅消息!彭博社最新推出BloombergGPT 在金融任务上的表现远超现有模型



FX168财经报社(香港)讯 周五(3月31日)最新消息,美国彭博社重磅发布为金融界构建的大型语言模型(LLM)——BloombergGPT。该模型依托彭博社的大量金融数据源,构建了一个3630亿个标签的数据集,支持金融行业内的各类任务。
彭博社主要是一家金融数据公司,数据分析师在公司成立的40年的时间里收集了大量的金融文件,拥有广泛的金融数据档案,涵盖一系列的主题。
根据彭博社最新发布的报告显示,其构建迄今为止最大的特定领域数据集,并训练了专门用于金融领域的LLM,开发了拥有500亿参数的语言模型——BloombergGPT。
据悉,该模型在金融任务上的表现远超过现有模型,且在通用场景上的表现与现有模型也能一较高下。
在BloombergGPT相关论文中显示,BloombergGPT 的优势包括特定领域模型仍有其不可替代性且彭博数据来源可靠,金融相关任务上的性能明显优于现有模型等。
彭博报告指出,自然语言处理(NLP)在金融科技领域应用广泛且复杂,应用范围包括情感分析、命名实体识别和问答系统等。大型语言模型(LLM)已经被证明在许多任务中有效;然而,在文献中并没有报道专门为金融领域设计的 LLM。在这个研究中,我们介绍了BloombergGPT,一个拥有500亿参数的语言模型,它通过广泛的金融数据进行训练。
报告显示:“我们基于彭博社的数据源构建了3630亿个标签的数据集,并将其从通用数据集中添加到其中,这可能是目前金融领域最大的数据集之一。我们使用标准 LLM 基准、开放金融基准和一组内部基准来验证BloombergGPT,这些方法最能准确地反映我们的意图使用。我们的混合数据集训练导致在金融任务中比现有模型表现优异,而无需牺牲通用 LLM 基准的性能。此外,我们解释了我们的建模选择、训练过程和评估方法。作为下一步,我们计划发布训练日志( Chronicles),详细描述我们在训练BloombergGPT 时的经历。”

(截图来源:Paper Reading)
报告指出,从测试结果来看,BloombergGPT在五项任务中的四项(ConvFinQA,FiQA SA,FPB和Headline)表现最佳,在NER(Named Entity Recognition)中排名第二。因此,BloombergGPT具有其优势性。
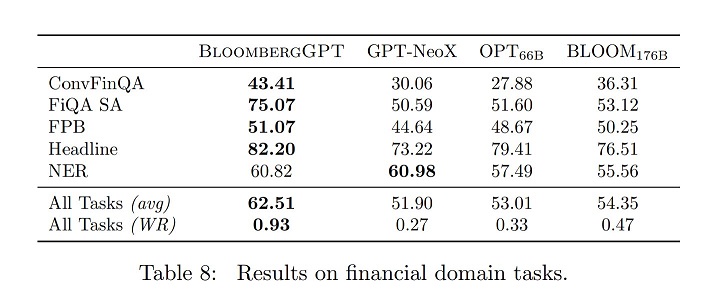
(截图来源:彭博社)
拥有近20万粉丝的推特账号“外汇交易员”在推特上写道,彭博发文介绍BloombergGPT,依托自身海量金融数据,构建了一个3630亿个标签的数据集,基于通用和金融业务的场景进行了混合模型训练。彭博称其在金融任务上超过了现有的模型(信息理解、情感分析、标注、实体命名等),而在通用场景上的表现则与之相当甚至优于现有模型。
(截图来源:推特)
就最新的BloombergGPT,ChatGPT如何看待自己的竞争对手?
ChatGPT认为,BloombergGPT是专门为金融领域开发的一种语言模型,可以更好地处理金融领域的数据和任务,并且在金融领域的基准测试中表现出色。这将有助于金融从业者更好地理解和应用自然语言处理技术,促进金融科技的发展。BloombergGPT还可以为其他领域的语言模型的发展提供参考和借鉴。总的来说,BloombergGPT是一个有益的技术创新。
成立于1981年的美国彭博资讯公司,是全球最大的财经资讯公司,其前身是美国创新市场系统公司。
彭博社是全球最大的金融信息服务供应商,其数据终端系统“彭博专业服务”可以帮助客户查阅和分析实时的金融市场数据,并进行交易。使用该数据终端的客户遍布全球,包括交易员、投行、美联储、美国其他官方机构以及全球各大央行等。
相关文章

交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管93.02
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.21
- 监管中FXBTG10-15年 | 澳大利亚监管 |83.48
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47
- 监管中OneRoyal10-15年 | 澳大利亚监管 | 塞浦路斯监管 | 瓦努阿图监管85.75
- 监管中易信easyMarkets15-20年 |澳大利亚监管 | 塞浦路斯监管85.38
- 监管中FXCC10-15年 | 塞浦路斯监管 | 直通牌照(STP)85.26